프로그래밍
내가 생각하는 머신러닝의 학습 분야는 크게 세 가지다. 먼저 프로그래밍이다. 머신러닝을 배우기 위해 프로그래밍은 필수라고 생각한다. 머신러닝의 이론을 연구하는 정말 소수의 대단한 과학자가 아니고서야 프로그래밍 없이 머신러닝을 공부한다는 것은 상상할 수 없다. 그러면 자연스럽게 어떤 언어를 배워야 하는가에 대한 고민을 많이 하게 될 것이다. `요즘에는 Python이 유행하더라', `R이 배우기는 쉽더라', `그래도 빠른 계산이라면 C를 배워야지' 주변에서 어떤 언어가 중요한지 논쟁은 너무 쉽게 찾아볼 수 있다. 하지만, 만약 프로그래밍을 처음 접하는 사람이라면 별 고민할 필요가 없다. 맘에 드는 언어를 먼저 배우고 쓰면 된다. 시작할 때는 먼저 시도해 보는 것이 중요하지, 무엇으로 시작할 것인지는 크게 중요하지 않다. 프로그래밍의 개념을 익히고 나면, 앞으로 본인이 하게 될 일을 조금 더 쉽게 하거나, 주변 사람들과 협업하기 위해서는 어떤 언어를 알아야 할지 자연스럽게 깨닫게 될 것이다. 참고로 나는 R을 주로 사용하는 사람들과 협업을 해 왔다. 하지만 최근에는 Python을 사용하는 사람과 할 일이 조금씩 많아지면서 Python을 이용한 작업을 조금씩 늘려가고 있는 중이다. 프로그래밍에서는 `자료의 구조', '제어', '반복'의 개념이 중요하고, 자료 구조에 가장 많은 시간을 할애해야 할 것이다. 조금 더 공부를 한다면, 데이터의 전처리를 위해서 '파일의 입출력', '정규표현식'과 같은 개념들을 배우면 도움이 될 것이다.
확률/통계/수학
두 번째로 필요한 것은 확률/통계학/수학이다. 아마 이학계열이 아닌 사람들이 이 부분에서 가장 힘들어 할 것이다. 통계학은 배우는데 시간이 많이 걸린다. 수학 역시 마찬가지일 것이다. 관련한 많은 과목이 있겠지만 내가 배웠던 관련 과목 중 중요하다고 생각하는 과목을 나열하면 다음과 같다.
- 확률/통계
- 기초통계학 (1학년): 통계학의 기초로 랜덤의 개념을 배우고 추정, 검정에 대한 기초지식을 쌓는다.
- 확률의 개념 및 응용 (2학년): 확률변수, 확률분포, 기대값을 배우고 확률과정에 대한 기초지식을 쌓는다.
- 수리통계학 I,II (2~3학년): 우도함수와 추정방법에 대한 개념을 배운다.
- 베이지안 통계학 (4학년): 베이지안 통계의 철학과 모델링, 추정방법을 배운다.
- 다변량분석 (4학년): 다변량졍규분포의 성질과 주성분/요인분석 개념을 배울 것이다. 아마도 차원 축소에 대한 아이디어를 얻을 수 있을 것이다.
- 기계학습 (4학년): 기계학습 방법론의 기초를 배운다. 경험적 위험함수를 통해 모형화 하는 방법을 배우게 될 것이다.
- 수학
- 미적분학 I (1학년): 미적분의 기초지식을 쌓는다.
- 선형대수 (2학년): 벡터공간을 배우고 행렬을 통해 계산과정을 간결하게 쓸 수 있음을 배운다. 행렬의 분해를 통해 데이터가 가지고 있는 정보를 추출하는 기본적인 개념을 배울 수 있다.
- 해석개론 (3학년): 극한의 개념을 배운다.
계산
마지막으로 필요한 것이 '계산'이다. 확률/통계/수학의 지식으로 모형화를 하고, 프로그래밍을 통해 모형을 컴퓨터에게 이해시킬 능력이 생기면 그 다음은 계산하는 것이 필요하다. 주로 계산이라함은 주어진 목적함수를 제약조건에서 최소화하는 '최적화 문제'를 푸는 것과, 어떤 모형에서 설정한 복잡한 확률분포 모형으로 부터 랜덤 샘플을 추출하는 '몬테카를로 시뮬레이션' 두 문제로 압축된다. 이를 위해서는 다음과 같은 교과목을 추천한다.
- 통계계산 (3학년): 간단한 수치계산과 랜덤샘플의 생성 방법을 배운다.
- 최적화 (4학년): 정형화된 최적화 문제를 푸는 여러 알고리즘을 배우고 그 해의 수렴성을 공부한다.
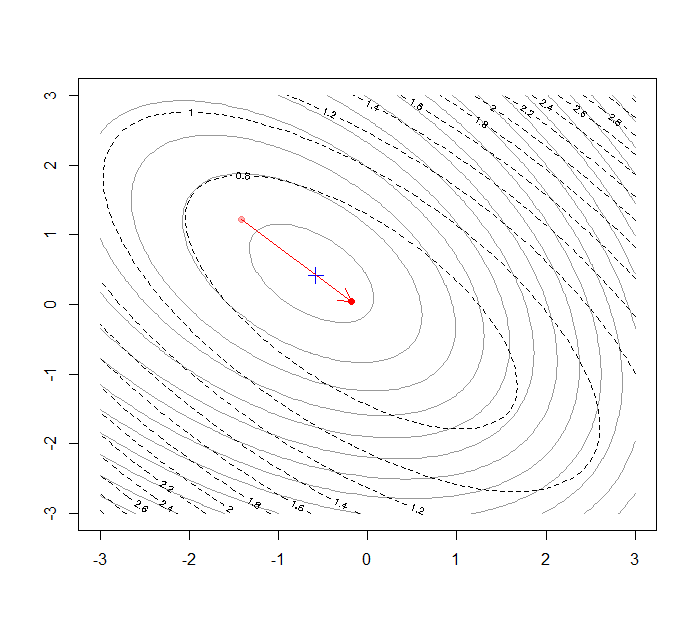 이차근사 알고리즘의 개념도: X점은 optimal point, 연한색 붉은 점은 current solution, 점선은 current solution에서 근사한 이차식의 contour, 진한색 붉은 점은 근사한 이차식의 optimal point
이차근사 알고리즘의 개념도: X점은 optimal point, 연한색 붉은 점은 current solution, 점선은 current solution에서 근사한 이차식의 contour, 진한색 붉은 점은 근사한 이차식의 optimal point
지금까지 살펴본 과목들을 학년별로 나열하면 대충 어떻게 공부를 해야할 지 감이 올것이다. 이 많은 과목들 중에서 특히 '선형대수'는 중요한 과목이다. 선형대수를 통해 복잡한 계산들이 얼마나 간결하게 표현되고 그것을 통해서 우리가 많은 것을 얻을 수 있다는 것을 배우게 될 것이다. 지금 머신러닝을 공부하고 있는 사람들 중에서도 위 과목들 중에서 혹시 빠뜨린 것이 있다면, 따로 공부해보길 추천한다.