RNN cell Review
아래는 두 개의 층을 가진 단방향 RNN cell의 구조를 보여줍니다.
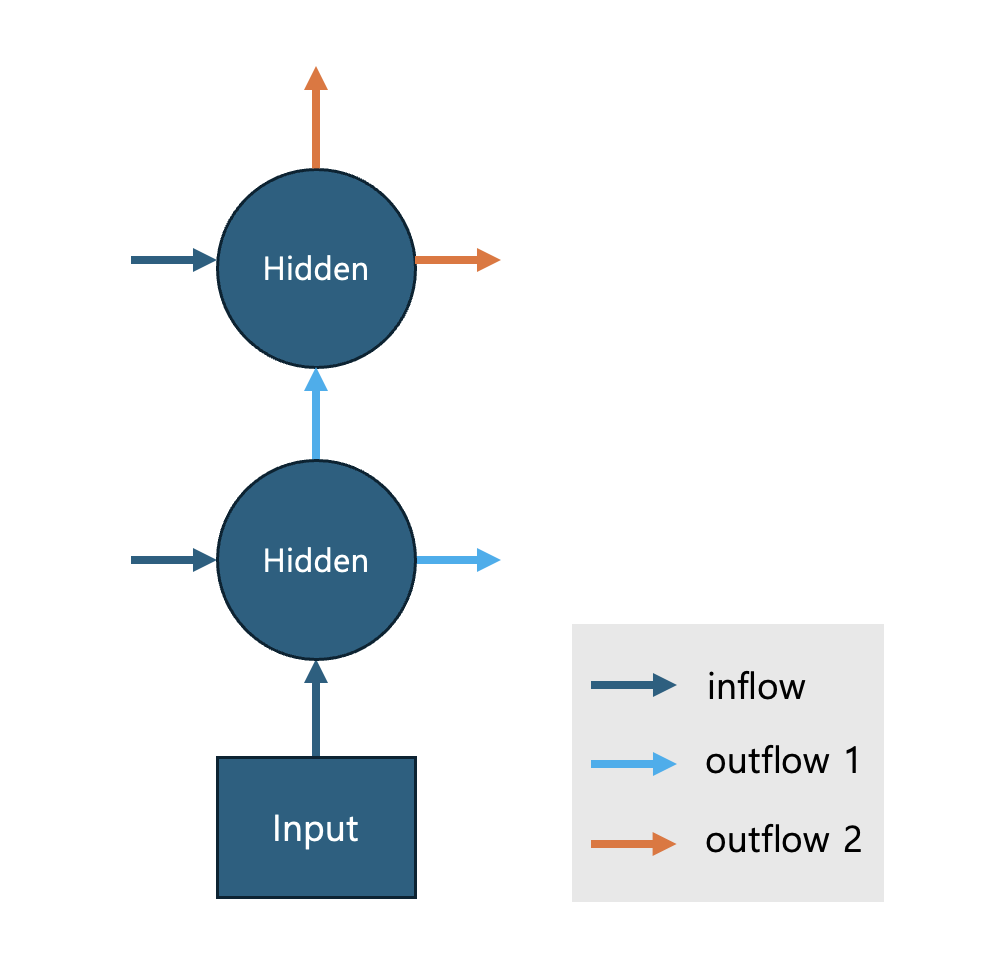
RNN cell 은 어떤 시점 $t$에서 정보를 처리한다고 가정하겠습니다. [그림 1]의 RNN cell 은 $(t-1)$ 시점에서 처리된 두 개의 값과 $t$ 시점에 얻어진 Input 을 받아 정보를 처리합니다. $(t-1)$ 시점의 값은 [그림1] 의 inflow 중 Hidden 으로 들어오는 두 개의 화살표로 표시하였습니다. $t$ 시점의 정보는 Input 에서 Hidden 으로 표시된 inflow 화살표로 표시하였습니다.
outflow 1 은 RNN의 첫번째 층의 Hidden 노드에 출력값으로 두 번째 층의 Hidden 노드로 전달되며 동시에 같은 값이 다음 (t+1) 시점의 RNN cell 로 전달됩니다. (t+1) 시점의 RNN cell의 첫번째 Hidden 노드는 이 값을 inflow 값 중 하나로 받게 됩니다. 마찬가지로 outflow 2 는 두번째 층의 출력값으로 RNN cell의 output 이며 (t+1) 시점 RNN cell의 두 번째 hidden node 의 입력값이 됩니다. 아래 그림 2를 통해 정보의 전달 과정을 확인하세요.
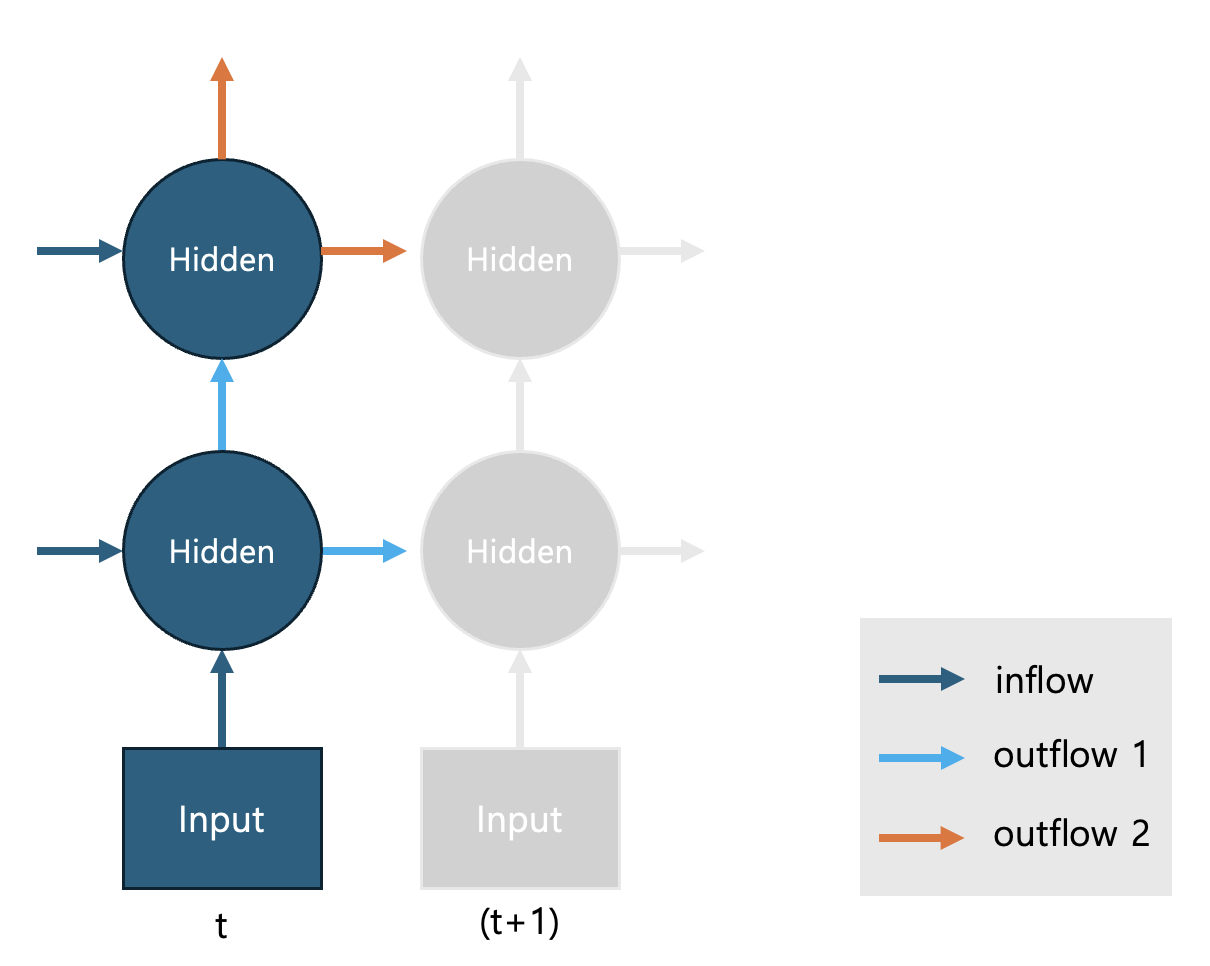
앞서 살펴본 바와 같이 특정한 RNN cell 을 정의하기 위해서는 입력값, 잠재값, 잠재층의 개수 등을 정해야 합니다. 따라서 RNN cell 을 명시하기 위해서는 다음과 같은 세부사항을 정해주어야 합니다.
- input_size: 입력 변수는 몇 차원인가?
- hidden_size: 잠재 변수는 몇 차원인가?
- num_layers: 잠재층은 몇 개?
- bidirectional: 위 에서 따로 설명하지는 않았지만 역방향 RNN을 추가로 사용할 것인가?
다음과 같이 입력하겠습니다.
# 필요 패키지 로드
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# RNN cell 입력값 설정
input_size = 4
hidden_size = 5
num_layer = 2
bidirectional=False
다음으로 RNN cell 을 만들겠습니다.
# RNN cell 만들기
rnn = nn.RNN(input_size=4, hidden_size=6, num_layers=2,
bidirectional=False,
batch_first=True).to(device)
입력값이 4차원이고, 잠재변수가 6차원이고, 두 개의 층을 가지며, 단방향인 RNN cell 이 rnn 이라는 이름으로 만들어졌습니다. (batch_first = True 는 다음에 이어서 설명하겠습니다.) rnn은 시계열로 된 입력값을 받는 경우 반복문을 통해 출력값을 만듭니다. 먼저 rnn이 받는 입력값에 대해서 설명하겠습니다.
우리는 하나의 시계열 입력 데이터를 생각하겠습니다. 총 다섯 시점의 데이터로 구성되어 있고 한 시점의 정보는 4차원으로 표현되어 있습니다.
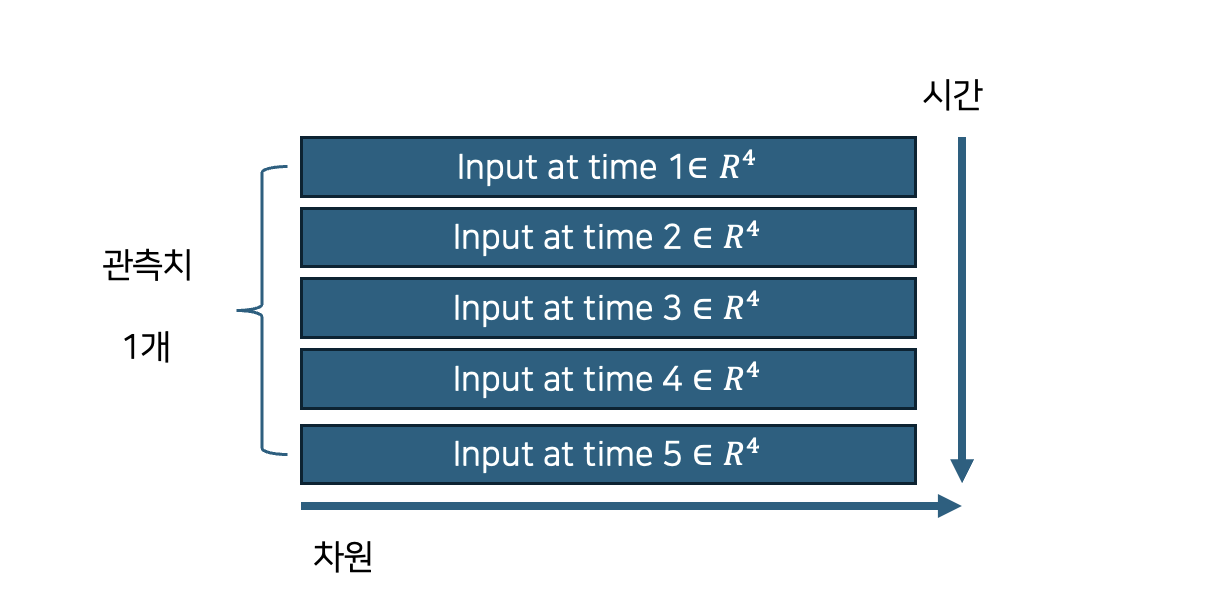
[그림 3]은 길이가 5, 입력 데이터의 차원이 4인 1개 데이터의 개형을 나타냅니다. 형태는 5행 4열인 행렬, 혹은 모양이 (5,4)인 2차원 배열입니다. 첫번째 행 벡터는 시계열의 가장 첫번째 값으로 일반적으로 주어진 계열에서 현 시점을 기준으로 시간상 가장 첫번째 값에 해당합니다. 두 번째 행벡터는 시간상 두번째 값에 해당합니다. 각 시점의 데이터는 행 방향으로 정렬됩니다. 한편 한 시점의 데이터는 열의 개수 만큼의 변수로써 표현됩니다. [그림 3] 은 한 시점의 값을 4차원 벡터로 표시하고 있음을 알 수 있습니다.
rnn의 입력값은 길이가 길수로 행의 길이가 길어지고 각 시점에 대한 표현형이 풍부해질 수록 (높은 차원으로 표현될 수록) 열의 크기가 커집니다. 이는 언어모형에서 이용되는 입력값과 동일한 형태를 가지며 자세한 사항은 (여기)를 참고하세요.
rnn은 2개 이상의 시계열을 처리할 수 있도록 만들어졌습니다. 즉 다수의 2차원 배열을 rnn 입력값으로 넣을 수 있습니다. 이를 위해서 rnn 은 하나의 2차원 배열을 입력값으로 받는 것이 아니라 2차원 배욜을 쌓아놓은 형태, 즉 3차원 배열을 처리할 수 있게 만들어져있습니다. 예를 들어 (5,4) 배열이 10개, 다시 말해 시계열자료 10개가 있다고 한다면 rnn 은 3차원 배열 (10,5,4)를 받을 수 있습니다. 이런 이유로 인해 데이터가 (5,4)인 2차원 배열 1개는 형태를 (1,5,4)로 변환하여 rnn 입력으로 사용해야 합니다.
여기서 언급해야 할 부분은 우리가 지금까지 논의한 rnn 입력데이터의 형태가 결국 (배치, 입력값의 길이, 차원)의 형태라는 것 입니다. 이런 형태의 입력값을 처리하도록 rnn = nn.RNN(..., batch_first=True) 으로 설정해야 합니다. "기본적으로 batch_first=False 로 되어 있어 주의해야할 부분입니다." batch_first=False 인 경우에는 (입력값의 길이, 배치, 차원)로 입력값을 구성해야 합니다.
그렇다면 왜 입력데이터의 형태를 알아보기 어려운 batch_first=False 를 기본값으로 만들었을까요? 개인적인 생각이지만 그 이유가 RNN의 재귀성에 있을 것으로 같습니다. 같은 구조가 반복되니 데이터 샘플별로 RNN cell 의 값을 계산하는 것 보다는 시점별로 모든 데이터를 계산해 나가는것이 코딩의 편의성이나 효율성에서 유리해보입니다. 그러면 우리는 10개의 시계열인데 하나의 시계열이 길이가 5, 각 시점별 값이 4차원인 데이터를 만들어보겠습니다.
x = torch.randn(size = (10,5,4)).to(device)
여기서 만든 $x$를 rnn에 입력할 것입니다. 먼저 rnn의 출력과정을 [그림 4]로 살펴보겠습니다.
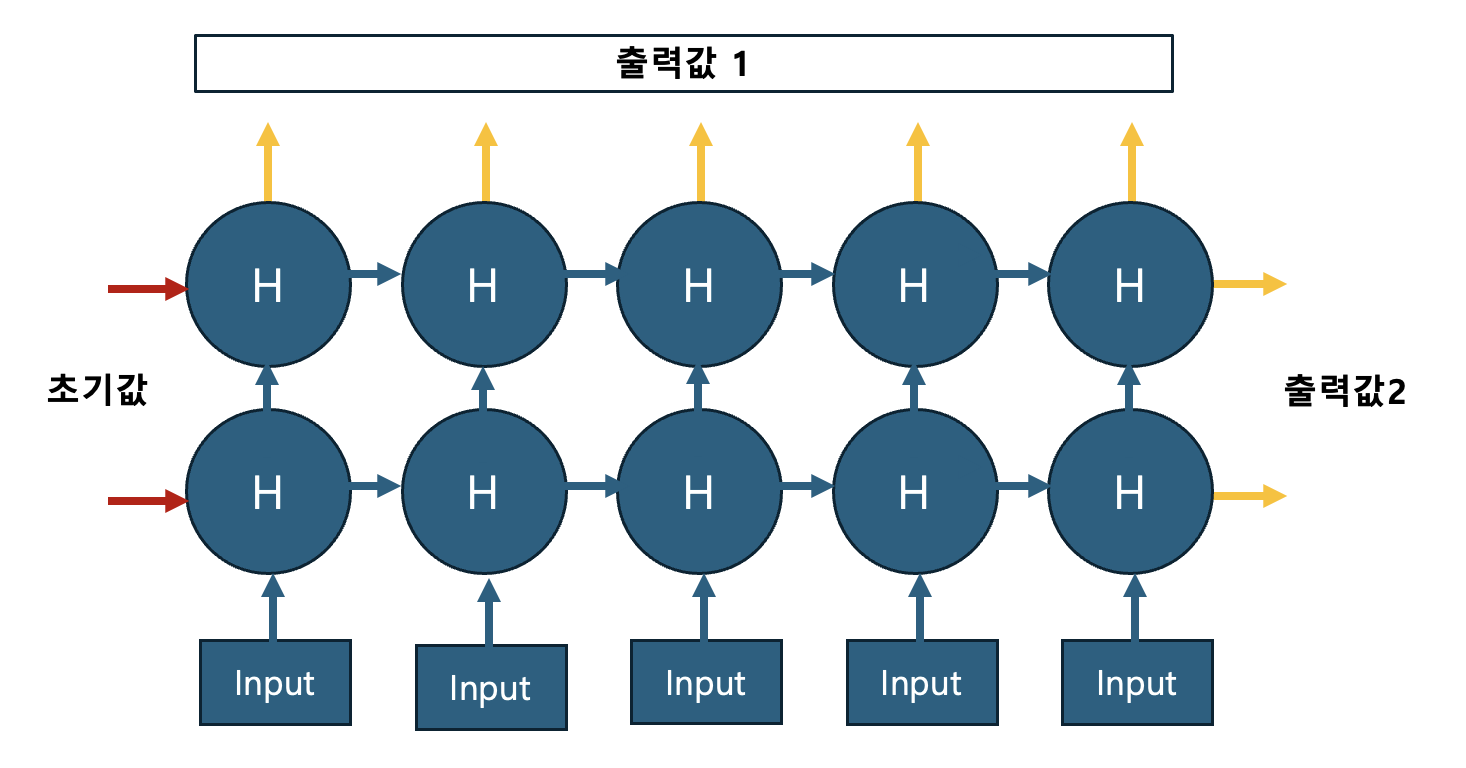
rnn 은 그림4와 같이 시간의 흐름에 따라 재귀적인 방식으로 출력값을 만들어냅니다. 그렇기 때문에 잠재변수에 대한 초기값이 필요합니다. rnn 모형의 유연성을 위해서 이 초기값을 항상 입력하도록 되어 있습니다. (이렇게 rnn 을 설계한 이유는 Seq2Seq에서 알아보겠습니다.) 다음과 같이 초기값 h0를 설정해줍니다. 지금은 x가 2개의 층, 10개의 시계열 데이터이며 rnn 의 잠재변수 차원이 6이므로 초기값의 크기를 (2,10,6)로 맞춰 만들어 줍니다. batch_first 의 값과는 상관없이 항상 같은 h0 의 형식은 같은 형태를 따릅니다. 만약 bidirectional = True 사용하고 있다면 역방향 잠재변수층이 있으므로 층의 개수를 2배 하여 (4,10,6)크기를 가지는 h0 를 만들어줍니다.
h0 = torch.zeros(2, x.shape[0], 6).to(device)
out, h = rnn(x, h0)
out은 [그림4]에서 출력값1이, h에는 출력값 2가 저장되어 있습니다. out 은 10개 시계열, 길이 5, 잠재변수 6차원 정보를 저장하고 있어 크기가 (10,5,6) 입니다. h는 2개의 층 10개 시계열, 잠재변수 6차원 정보를 저장하고 있어 크기가 (2,10,6) 입니다. 특별히 h는 시계열 정보의 시간적 정보를 모두 포함하고 있어 이를 맥락벡터(Context Vector)라 부르기도 합니다.
두번째 시계열자료의 결과물 1을 얻고 싶으면 out[1,:,:] 을 참조하면 됩니다. 두번째 시계열의 결과물 2를 얻고 싶으면 h[:,1,:] 을 참조하면 됩니다. 참고로 h[1,1,:] 은 두번째 층의 두번째 시계열의 마지막에 위치한 잠재변수(맥락벡터)이므로 out[1,-1,:] 와 같은 값을 가집니다.