RNN Encoder
용어정리
- RNN cell; 과거시점의 잠재변수와 현재시점의 입력변수를 받아 현재시점의 잠재변수로 변환하는 함수
- RNN: RNN cell이 입력데이터의 길이만큼 연결된 함수
- rnn: pytocrch 의 nn.RNN 으로 만들어진 RNN 함수
RNN 인코더는 시계열 입력값을 RNN Cell 을 이용하여 재귀적인 연산을 수행합니다. 개략적인 함수의 형태를 아래와 같습니다. t 시점의 첫 번째, 두 번째 잠재층의 변수를 $h_t^{(1)}$, $h_t^{(2)}$ 라 하겠습니다. 이 잠재변수는 다음 같은 방식으로 RNN 내에서 재귀적으로 처리됩니다. $$h^{(1)}_{t} = f_1(x_{t}, h^{(1)}_{t-1})$$ $$h^{(2)}_{t} = f_2(h_t^{(1)}, h^{(2)}_{t-1})$$ $t = 1, \cdots, T$. 여기서 $f_1$은 첫 번째 잠재층에서 변환함수고, $f_2$는 두 번째 잠재층에서 변환함수입니다.
다음은 시계열 주가데이터를 불러옵니다. 여기서는 로그 수익률을 만듭니다. 아래의 create_inout_sequences 함수는 원 시계열을 [그림 1]과 같은 형태로 분할하여 리스트에 저장합니다. input_window_size는 입력계열의 길이 output_window_size는 출력계열의 길이입니다.
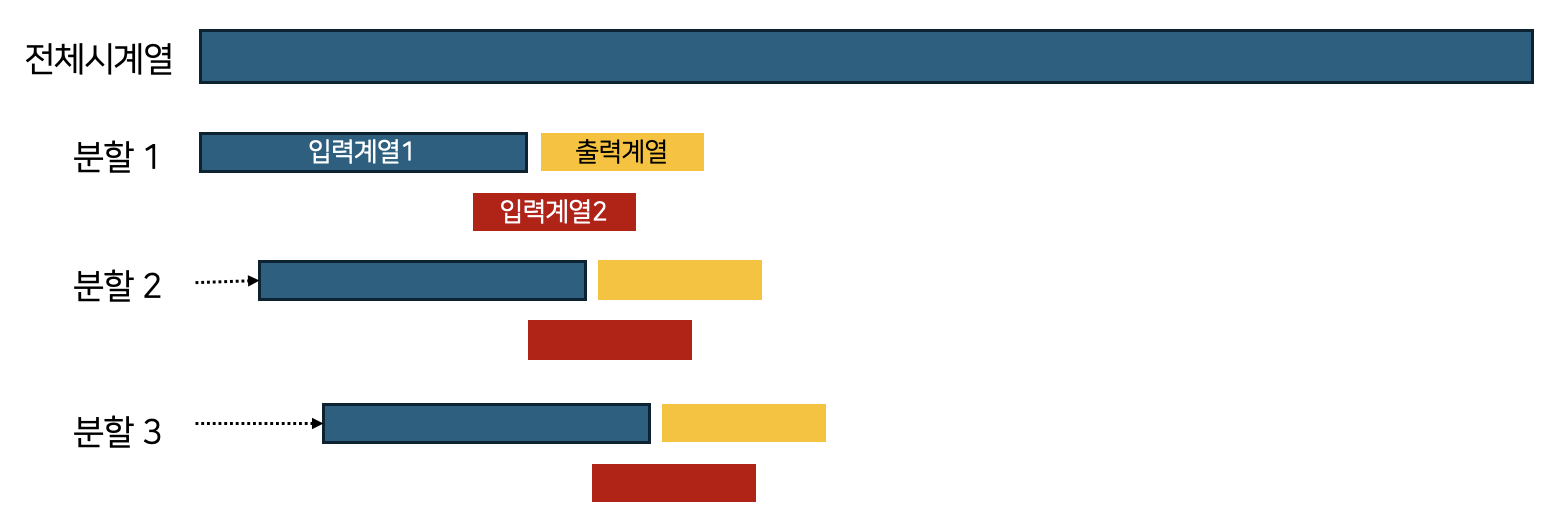
[그림 1]각각의 분할이 모형학습에 사용할 데이터 관측치가 됩니다 [그림 1]에는 두 가지의 입력계열이 있는데 우선 우리는 입력계열1을 사용합니다. (나중에 확인하겠지만, 입력계열2는 교사학습(teacher forcing)에 사용할 데이터입니다)
# Load data
df = pd.read_csv('http://ranking.uos.ac.kr/class/RB/stock_data.csv')
x_0 = np.array(df['Close'][0:-1])
x_1 = np.array(df['Close'][1:])
x = np.log(1-(x_1-x_0)/x_0)
# window size 설정
input_window_size = 6
output_window_size = 3
# 입력 시퀀스와 출력 시퀀스 정의
def create_inout_sequences(input_data, input_window_size,
output_window_size):
inout_seq = []
L = len(input_data)
s1 = input_window_size
s2 = output_window_size
for i in range(L - s1 - s2):
train_seq = input_data[i:(i+s1)].reshape(s1,1)
train_seq = train_seq.astype(np.float32)
# teacher forcing
train_seq2 = input_data[(i+s1-1):(i+s1+s2-1)].reshape(s2,1)
train_seq2 = train_seq2.astype(np.float32)
# label
train_label = input_data[(i+s1):(i+s1+s2)].reshape(s2,1)
train_label = train_label.astype(np.float32)
inout_seq.append([train_seq ,train_seq2, train_label])
return inout_seq
# 입력 시퀀스와 출력 시퀀스 생성
train_data = create_inout_sequences(x, input_window_size,
output_window_size)
print('input:', train_data[0][0].shape)
print('input for teacher forcing:', train_data[0][1].shape)
print('output:', train_data[0][2].shape)
print('train_data:', len(train_data))
다음으로 우리가 사용할 RNN의 모형 계수들을 정하겠습니다.
- input_size: 입력열에서 한 시점의 데이터 차원
- hidden_size: 잠재변수의 차원
- num_layers: RNN cell 의 레이어 수
# Define hyperparameters
input_size = 1
hidden_size = 5
num_layers = 2
bidirectional = False
우리가 만들 Encoder 는 RNN의 길이 6의 입력열을 받아서 맥락벡터(convext vector)를 출력하는 함수입니다. 맥락벡터는 Encoder 의 끝에 있는 두 개의 잠재층에서 가져오겠습니다.
# Define the encoder
class myEncoder(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super(myEncoder, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers,
batch_first=True)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.shape[0],
self.hidden_size).to(device)
_, h = self.rnn(x, h0)
return h
정의한 클래스 myEncoder가 올바른 rnn을 만들 수 있는지 확인해보겠습니다. 먼저 rnn 인스턴스를 만듭니다. 다음 rnn 에 입력값으로 사용할 데이터를 train_data 에서 가져옵니다. train_data[0][0]는 첫번째 관측치에 대한 입력계열1입니다. 이 입력계열1은 형태가 (6,1)인 numpy.array 입니다. rnn 이 입력계열1을 처리할 수 있도록 tensor 로 변환하고 unsqueeze(0)를 사용하여 형태를 (batch_size, seq_length, hidden_size) 인 (1,6,1) 로 맞춰 줍니다.
(참고) myEncoder 의 출력값의 형태는 잠재변수 초기값의 크기 (num_layers, x.shape[0], hidden_size)와 같습니다.
# 확인
rnn = myEncoder(input_size, hidden_size, num_layers).to(device)
x = torch.tensor(train_data[0][0]).unsqueeze(0).to(device)
# 입력계열1의 형태 확인
x.shape
# rnn 출력값 형태 확인
rnn(x).shape
다음으로 dataloader 를 통해 rnn이 출력값을 잘 만들어내는지 확인합니다. train_data[0] 은 입력계열1, 입력계열2, 출력계열로 만들어져 있기 때문에 for 문에서 각 원소를 따로 받아옵니다.
# dataloader 로 확인
batch_size = 5
train_loader = torch.utils.data.DataLoader(train_data,
shuffle=False, batch_size=batch_size)
encoder = myEncoder(input_size=1, hidden_size=5, num_layers=2).to(device)
for inputs, _, _ in train_loader:
input = inputs.to(device)
h = encoder(input)
print(h.shape)
break
인코더가 완성되었습니다.