안녕하세요. 인공지능 만들기 Coding Master Class에 오신 것을 환경합니다. 본 내용은 파이토치의 기초과정으로 기본적인 파이썬의 사전 지식을 필요로 합니다. 이후 코드 블럭에 있는 텍스트를 복사하여 colab 에서 실습합니다. 시작합시다!
Numpy 패키지 리뷰
파이썬에서 벡터와 행렬의 다루는 numpy 패키지의 사용방법에 대해서 리뷰해봅니다. 먼저 2차원 배열 (행렬)을 만드는 예제입니다. 모든 값이 0인 5행 3열인 행렬을 만들어 봅시다.
# 1. 0으로 초기화된 5x3 행렬 생성
import numpy as np
z = np.zeros((5, 3))
print(z)
print(z.dtype) # 데이터 타입 출력
변수 z를 출력해보고 z의 값의 데이터형을 확인해보았습니다. z가 가진 0 값이 'float64'임을 알 수 있습니다. Float64는 64비트를 사용하여 실수를 표현하며, 약 15~17자리의 십진수 유효 숫자를 표현할 수 있는 정밀도를 제공합니다. 최소값은 약 $-1.8 \times 10^{308}$에서 최대값은 약 $1.8 \times 10^{308}$까지 가능합니다. 만약 사용하고자 하는 값의 범위가 작거나 정밀도가 낮아도 되는 경우 메모리를 더 작게 차지하는 데이터 형을 사용할 수도 있습니다. 이 경우 메모리 용량 및 계산 속도에서 이득을 볼 수 있습니다. 다음 예를 봅시다.
# 2. 1로 초기화된 5x3 행렬 생성, 데이터 타입은 int16
i = np.ones((5, 3), dtype=np.int8)
print(i)
print(z.dtype) # 객체 타입 확인
int8은 8비트 정수를 나타내는 데이터 타입입니다. 이는 부호가 있는(signed) 8비트 정수를 표현하며, 값의 범위는 -128부터 127까지입니다.
다음은 랜덤한 값을 채워넣은 2차원 배열을 만드는 코드입니다. rand 을 사용하여 배열의 값을 0과 1사이의 균등분포로 부터 생성한 난수로 채워봅시다.
# 3. 랜덤 시드 설정 및 랜덤 행렬 생성
np.random.seed(1729)
r1 = np.random.rand(2, 2)
print('A random array:')
print(r1)
print(r1.dtype) # 데이터 타입 출력
만약 균등분포가 아닌표준정규분포로부터 난수 행렬을 만드는 경우에는 random.randn 함수를 사용하면 됩니다. 크기가 (10,3) 인 행렬을 만들어 봅시다.
다음은 모든 원소를 1로 채워넣는 코드입니다. 데이터 타입이 무엇인지도 같이 확인해보세요.
# 4. 1로 초기화된 2x3 행렬 생성
ones = np.ones((2, 3))
print(ones)
numpy 로 만든 행렬과 벡터는 연산이 가능합니다. 먼저 스칼라 곱 연산을 알아보겠습니다.
# 5. 2로 초기화된 2x3 행렬 생성
twos = np.ones((2, 3)) * 2
print(twos)
덧셈 연산도 가능합니다. 덧셈을 할 때 행렬/벡터의 크기가 맞지 않으며 계산에서 오류가 생깁니다. 배열의 크기는 "배열이름.shape" 를 실행하여 확인할 수 있습니다.
# 6. 요소별 행렬 덧셈
threes = ones + twos
print(threes)
print(threes.shape) # 결과 행렬의 크기 확인
행렬의 곱셈은 기계학습 모형을 만드는데 매우 중요한 연산입니다. 회귀모형에서 관측치의 개수가 50개 변수가 20 개 인 데이터가 있고, 그 데이터가 numpy array $X\in \mathbb{R}^{50\times 20}$로 저장되어 있다고 합니다. 이 변수에 회귀계수 $\beta \in \mathbb{R}^{20 \times 1}$ 가 주어져있을 때 $\widehat {y}$ 는 $X\beta$ 로 계산됩니다. 이를 numpy 로 다음과 같이 계산할 수 있습니다.
# 7. 행렬 곱셈 예제
x = np.random.rand(50, 20)
b = np.random.rand(20, 1)
print(x @ b)
인공지능 모형에서는 3차원 이상의 배열을 사용하기도 합니다. 예를 들어서 RGB 컬러로 표현된 사진이 한 장 있다고 가정합니다. 이 사진의 크기는 세로(Height) 가 20 픽셀, 가로(Width)가 50 픽셀이며 Red, Green, Blue 채널로 입니다.
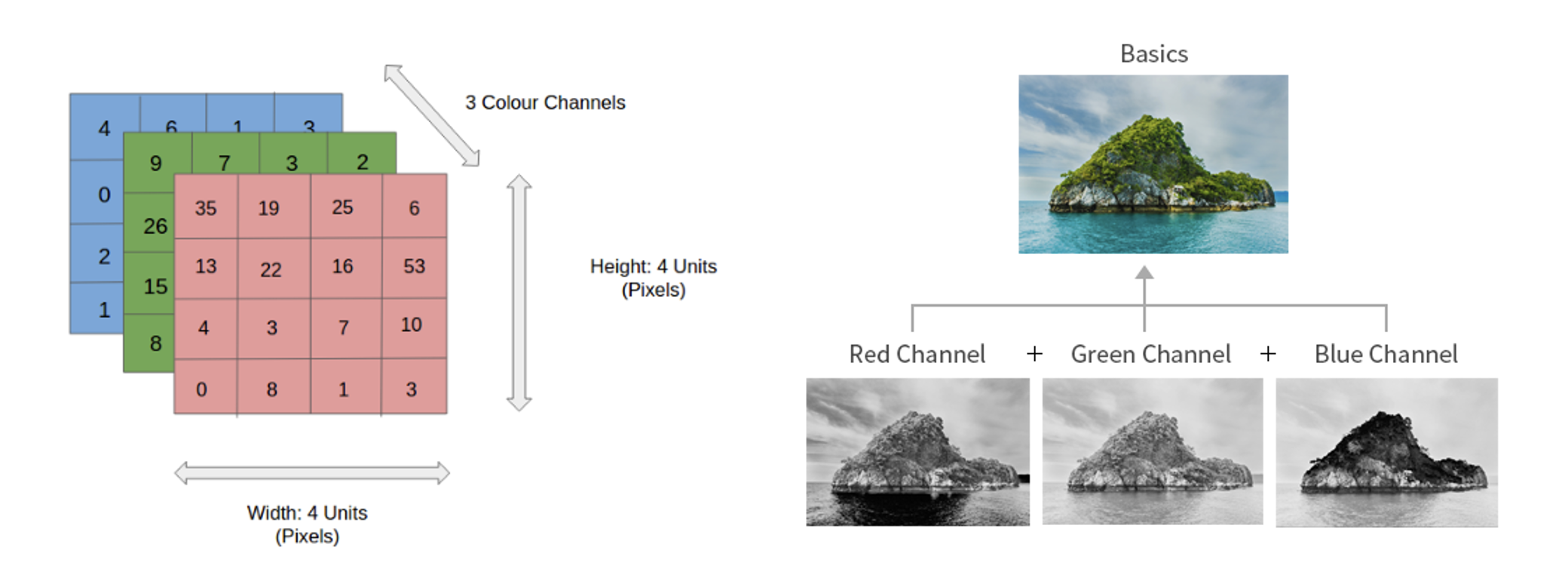
위 사진은 컬러이미지의 데이터 형식을 나타낸 그림입니다. 사진 데이터가 (channel, height, width) 로 구성되어 있다고 가정하겠습니다. 사진 x의 채널은 3개, height 는 20, width 50 이라 하면 x는 크기가 (3, 20, 50) 인 3차원 배열이 됩니다.
# 8. 빈 3x20x50 배열 생성
x = np.random.rand(3, 20, 50)
print(x.shape)
print(x)
배열의 값을 복사할 때 주의할 점을 상기해봅시다.
# 10. 객체 참조 및 복사
a = np.ones((2, 2))
b = a
a[0, 1] = 561 # a를 변경하면...
print(b) # ...b도 변경됨
배열의 값을 복사하여 독립적인 새로운 변수를 만들기 위해서는 깊은 복사를 사용해야 합니다. 다음 예에서 새로 만들어진 변수의 특정한 값을 변경해도 원본 배열의 같은 위치의 값이 변화하지 않음을 확인하세요.
# 11. 깊은 복사
a = np.ones((2, 2))
b = a.copy()
a[0, 1] = 561 # a를 변경하면...
print(b) # ...b는 변경되지 않음
Tensor 의 생성과 연산
딥러닝의 모형 적합에 사용하는 pytorch 패키지는 모형 내부의 연산을 위해 tensor 라는 특별한 변수로 데이터를 읽습니다. 파이썬에서 외부에서 데이터를 읽거나 내부에서 데이터를 생성하는 경우 pandas.DataFrame 형식이나 numpy.array 형식의 데이터를 사용하기 때문에 pytorch 에서 사용하는 tensor 로 데이터 변환이 이루어져야 합니다. 여기서는 먼저 텐서의 형식을 가지는 데이터를 만들어 보고, numpy.array 데이터를 tensor 로 변환하는 방법을 알아보겠습니다.
먼저 모든 값이 0 인 5행 3열 텐서를 만들어 봅니다. torch.zeros 함수를 사용하면 만들 수 있습니다.
# 1. 5x3 크기의 0으로 초기화된 텐서 생성
z = torch.zeros(5, 3)
print(z)
print(z.dtype) # 텐서의 데이터 타입 출력
값의 데이터 형식이 torch.float32 임을 확인할 수 있습니다. "dtype=torch.int16" 을 이용하여 int16 형식으로 텐서를 만들수 있습니다. torch.float32 (torch.float) 는 32비트 부동 소수점으로 기본 부동 소수점 타입입니다 torch.float16 (torch.half)는 16비트 부동 소수점으로 주로 GPU 연산에 사용됩니다. 인공지능 모형에 어떤 입력값을 넣을때 입력 데이터의 형식에 맞도록 데이터 형을 변경해야 하는 경우가 있으니 확인하고 적절한 데이터 형 변환을 수행을 해야 합니다.
# 2. 5x3 크기의 1로 초기화된 텐서 생성, 데이터 타입은 int16
z = torch.ones((5, 3), dtype=torch.int16)
print(z)
print(z.dtype) # 텐서의 데이터 타입 출력
데이터 타입 변환이 필요한 경우가 있는데 tensor_float = tensor.type(torch.float32) 처럼 데이터 형을 변경할 수 있습니다. 위 예제에서는 z_new = z.type(torch.float32) 를 실행하면 됩니다. 확인해보세요.
아래 예제는 가끔 모형을 실행할 때 발생하는 오류입니다. 입력 텐서인 input_tensor 의 데이터 형을 수정함으로써 오류를 해결하는 것을 확인하세요.
# 2.1 텐서의 데이터 형 변환이 필요한 경우
# 패키지 로드
import torch
import torch.nn as nn
# nn.Linear 레이어 정의
linear_layer = nn.Linear(4, 2) # linear_layer 는 함수입니다.
# 입력 텐서 만들기
input_tensor = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8]], dtype=torch.int32)
# 입력 텐서 출력
print("Input Tensor:")
print(input_tensor)
print("Input Tensor dtype:", input_tensor.dtype)
# 오류 발생
linear_layer(input_tensor)
# 수정
input_tensor = input_tensor.type(torch.float32)
linear_layer(input_tensor)
(0,1) 위의 균등분포로 난수를 생성하여 (2,2)인 행렬을 만들어 봅시다. torch.rand 를 이용해 텐서를 만들 수 있습니다. 데이터 형도 함께 확인해 봅시다.
# 3. 2x2 크기의 랜덤 텐서 생성
torch.manual_seed(1729)
r1 = torch.rand(2, 2)
print('A random tensor:')
print(r1)
print(r1.dtype) # 랜덤 텐서의 데이터 타입 출력
모든 값이 1로 채워진 텐서를 만들 수도 있습니다. torch.ones 함수를 사용하면 됩니다.
# 4. 2x3 크기의 1로 초기화된 텐서 생성
ones = torch.ones(2, 3)
print(ones)
다음은 텐서들의 연산을 살펴봅니다. 먼저 스칼라 곱과 덧셈을 확인해봅시다.
# 5. 5x3 크기의 0으로 초기화된 텐서 생성
# 2x3 크기의 2로 초기화된 텐서 생성
ones = torch.ones(2, 3)
twos = torch.ones(2, 3) * 2
print(twos)
threes = ones + twos # 같은 크기의 텐서 간 덧셈
print(threes)
print(threes.shape) # 결과 텐서의 크기 출력
텐서의 곱도 가능합니다. 행렬의 곱을 확인해보겠습니다.
# 6. 2x3 크기의 랜덤 텐서 생성
x = torch.rand(2, 3)
# 3x4 크기의 랜덤 텐서 생성
y = torch.rand(3, 4)
# 행렬 곱셈
print(x @ y)
텐서의 곱도 가능합니다. 행렬의 곱을 확인해보겠습니다.
# 7. 텐서 참조 및 복사
a = torch.ones(2, 2)
b = a
a[0][1] = 561 # a를 변경하면...
print(b) # ...b도 변경됨
a = torch.ones(2, 2)
b = a.clone()
a[0][1] = 561 # a를 변경하면...
print(b) # ...b는 변경되지 않음
텐서는 Numpy 의 배열과는 달리 자동 미분 기능을 가지고 있습니다. 텐서로 만들어진 함수는 텐서의 값들의 변화들에 대해 최종적인 함수의 변화량을 계산할 수 있는 기능을 가지고 있습니다. 이 기능으로 텐서로 만들어진 함수는 미분값을 쉽게 계산할 수 있고 인공지능 모형을 학습을 간편하게 수행할 수 있습니다. 아래의 "requires_grad=True" 옵션은 텐서가 만들어 질 때 자동 미분의 기능을 수행할 수 있도록 만들어짐을 의미합니다.
# 8. 자동 미분 기능을 갖는 텐서 생성
a = torch.rand(2, 2, requires_grad=True)
print(a)
한편 텐서의 깊은 복사는 clone 함수를 이용합니댜. 참고로 numpy 에서는 copy 이용했습니다.
# 9. 텐서 복사
b = a.clone()
print(b)
# 텐서의 그래디언트를 분리한 복사본 생성
c = a.detach().clone()
print(c)
텐서를 처음부터 생성하는 것이 아니라 이미 만들어진 numpy 객체로 부터 변환할 수도 있습니다.
# 텐서변환
import numpy as np
import torch
import torch.nn as nn
# numpy 배열 생성
a = np.array([10, 5, 3])
print(type(a))
# numpy 배열을 텐서로 변환
tensor_a = torch.Tensor(a)
print("1차원 텐서의 생성:", tensor_a)
torch.Tensor와 torch.tensor는 PyTorch에서 텐서를 생성하는 두 가지 방법이지만, 약간의 차이점이 있습니다. 다음은 두 방법의 주요 차이점입니다: torch.Tensor 는 기본적으로는 빈 텐서(uninitialized tensor)를 생성하고 이는 메모리에서 초기화되지 않은 값을 가지며, 무작위 값이 포함될 수 있습니다. 기본 데이터 타입은 생성되는 텐서의 기본 데이터 타입은 float32입니다. 아래를 참고하세요
# 텐서변환
# torch.Tensor를 사용하여 텐서 생성 (초기화되지 않은 값 포함)
a = torch.Tensor(2, 3)
print(a) # 초기화되지 않은 텐서, 무작위 값 포함
# torch.Tensor를 사용하여 리스트로부터 텐서 생성 (초기화됨)
b = torch.Tensor([1, 2, 3])
print(b) # 초기화된 텐서, [1, 2, 3]
torch.tensor는 Python의 list, tuple, numpy 배열 등으로부터 새로운 텐서를 생성하는 함수입니다. torch.tensor를 사용하면, 입력 데이터를 기반으로 초기화된 텐서를 생성합니다. 입력 데이터는 항상 초기화되며, 지정된 값으로 설정됩니다. torch.tensor를 사용할 때 dtype 인자를 사용하여 데이터 타입을 명시적으로 지정할 수 있습니다. 아래를 참고하세요
# 텐서변환
import torch
# torch.tensor를 사용하여 리스트로부터 텐서 생성 (초기화됨)
a = torch.tensor([1, 2, 3])
print(a) # 초기화된 텐서, [1, 2, 3]
# 데이터 타입을 지정하여 텐서 생성
b = torch.tensor([1, 2, 3], dtype=torch.float32)
print(b) # 초기화된 텐서, [1.0, 2.0, 3.0]
텐서에는 내부 원소값을 계산하거나 데이터형을 출력하는 함수를 내장하고 있습니다.
# 텐서의 합과 데이터 타입 출력
print("sum of a:", tensor_a.sum())
print("dtype of a:", tensor_a.dtype)
텐서의 값은 변경할 수 있습니다.
# 텐서의 요소 변경
tensor_a[0] = 1
print(tensor_a)
텐터의 차원 (축) 의 위치를 변경할 수 있습니다. 3채널이고 height 가 50, width 가 20인 사진 (3치원 배열) a를 하나 생각해봅시다. 이 배열을 (channel, height, width) 의 형식으로 만들어져 있어 그 크기가 (3, 50, 20) 으로 되어 있다고 가정하겠습니다.
# 3차원 텐서 생성 및 변형 예제
a = torch.rand(size=(3, 50, 20))
print("shape:", a.shape)
이 데이터에 이 사진이 첫 번째 사진이라는 것을 표시해야 된다고 가정합니다. 다시 말해 이 사진의 형식을 4D 인 (1, 3, 50, 20)로 표시해여 한다면 다음과 같은 함수를 이용할 수 있습니다. unsqueeze(0) 는 첫번째 차원 index 를 추가한다는 것입니다. 더 쉬운 예로 원소가 4개인 행벡터는 (4)의 크기를 갖지만, 2차원 행렬의 형식으로 (1,4)표시하는 것을 들 수 있습니다.
# 마지막 차원이 1인 4D 텐서로 변환
b = a.unsqueeze(0)
print("shape:", b.shape)
배열의 차원(축) 순서를 바꾸어야 하는 경우도 있습니다. 지금 데이터는 (channel, height, width) 형식으로 입력되어 있는데, 어떤 함수가 이 3D 텐서의 입력을 (width, height, channel) 로 요구한다면 우리는 입력값의 형식을 변경해야만 합니다. 이 경우 permute 함수를 사용합니다. 현재 (channel, height, width) 에서 인덱스 2 (width), 인덱스 1 (height), 인덱스 0 (channel) 의 순으로 배열하면 (width, height, channel) 이 만들어집니다. 아래에서 "a.permute(2, 1, 0)"를 확인하십시오.
# 텐서의 차원 순서 변경
print("shape:", a.shape)
permuted_a = a.permute(2, 1, 0)
print("shape:", permuted_a.shape)
차원을 축소해야 하는 경우가 있습니다. squeeze 함수를 사용하여 데이터 차원을 줄입니다.
# 마지막 차원을 줄여 3D 텐서로 변환
print("shape:", b.shape)
b = b.squeeze(0)
print("shape:", b.shape)
이미지 데이터 b 의 형태를 변환하는 reshape 는 다음을 참고하십시오
아래는 torch.tensor 를 이용하여 텐서를 만드는 방법을 보여주고 있습니다. torch.tensor 에 dtype 에 대한 별도의 지정이 없는 경우 만들어지는 텐서는 원래 데이터형을 유지합니다.
# numpy 배열의 데이터 타입 변환
a1 = np.array([1, 2, 3])
print("original dtype:", a1.dtype)
a1 = a1.astype('float32')
print("converted dtype:", a1.dtype)
a1 = torch.tensor(a1)
print("tensor dtype:", a1.dtype)
torch.tensor 에 dtype 에 대한 별도로 지정한 예를 살펴봅시다.
# torch.tensor를 사용한 데이터 타입 변환
a1 = np.array([1, 2, 3])
a1 = torch.tensor(a1, dtype=torch.float32)
print("tensor dtype:", a1.dtype)
to 함수를 이용하여 데이터 형을 변형하는 예를 확인해봅시다.
# 텐서의 데이터 타입 변환
a1 = np.array([1, 2, 3])
a1 = torch.tensor(a1)
print("original dtype:", a1.dtype)
a1 = a1.to(torch.float)
print("converted dtype:", a1.dtype)