시계열 모형 데이터 만들기
이번 시간에는 RNN을 이용한 비선형 시계열 회귀모형을 구성하는 코드를 살펴보겠습니다. 먼저 필요한 데이터를 다운로드 받습니다. 데이터는 주식의 거래량(Volume)과 시가(Open), 고가(High), 저가(Low), 종가(Close) 데이터로 이루어져 있습니다. 우리는 오늘의 로그수익률과 오늘을 포함한 과거 3일 데이터 (4일 동안의 5가지) 를 이용하여 다음날 종가(closing price)의 로그수익률을 예측하는 모형을 만들 것입니다.
$y_t \in \mathbb{R} $를 t 시점의 로그 수익률, $z_t \in \mathbb{R}^5$: t 시점의 주식의 거래량(Volume)과 시가(Open), 고가(High), 저가(Low), 종가(Close) 데이터, 그리고 $x_t = (y_t, z_t) \in \mathbb{R}^6$: t시점에 활용가능한 데이터라 하면 예측모형은 아래와 같습니다. \[\widehat {y}_{t+1} = f(x_t, x_{t-1},x_{t-2},x_{t-3})\] 우리는 $f$를 RNN 모형으로 만들고자 합니다. 먼저 데이터셋을 불러오겠습니다.
# 데이터셋 불러오기
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
device = 'cuda' if torch.cuda.is_available() else 'cpu'
torch.manual_seed(1)
if device == 'cuda':
torch.cuda.manual_seed_all(1)
# Load data
df = pd.read_csv('http://ranking.uos.ac.kr/class/RB/stock_data.csv')
df.head()
다음으로 종가를 이용해서 로그 수익률을 계산합니다. 로그수익률 데이터는 변수 y로 저장합니다. 위 코드에서 불러온 주가 데이터를 확인하세요. 이는 pandas DataFrame 으로 되어 있습니다. df['Close']의 데이터가 closing price 를 나타냅니다.
# 로그수익률의 계산
x_0 = np.array(df['Close'][0:-1])
x_1 = np.array(df['Close'][1:])
x = np.log(1-(x_1-x_0)/x_0)
y = x.copy() # len(y)
다음으로 설명변수를 만듭니다. 먼저 concatenate를 사용히여 날짜별로 변수가 6개인 데이터를 만든 후 scaler 를 사용하여 값을 표준화하였습니다.
# 입력데이터 만들기
x = x[:,np.newaxis] #x.shape
df1 = df.drop(index=df.index[0])
df1 = np.array(df1)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df1 = scaler.fit_transform(df1)
# df1.shape
x = np.concatenate( (x,df1), axis = 1) # x.shape
만들어진 데이터의 개형을 살펴보세요.
RNN 모형의 이해
우리가 만들 모형은 다음과 같습니다.
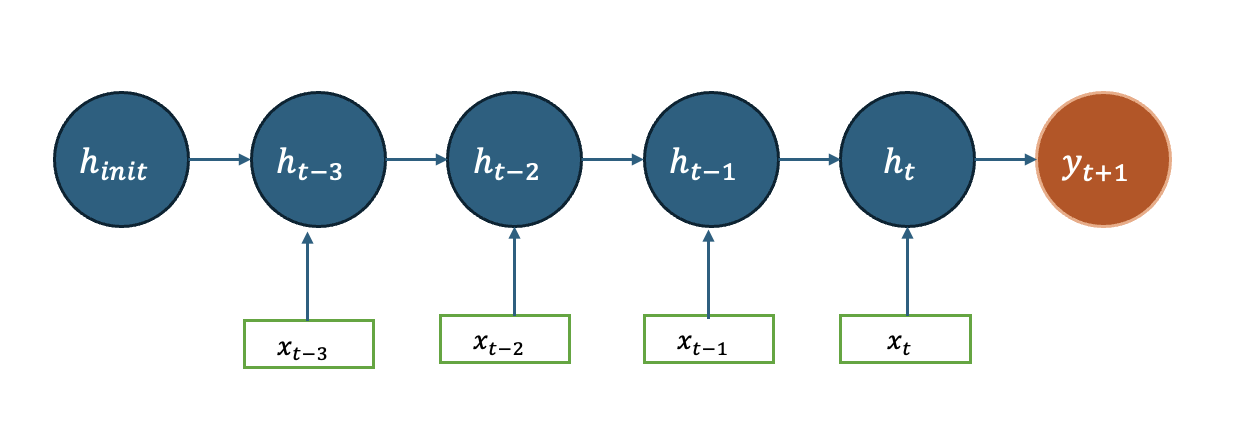
다음을 우리가 사용할 rnn 모형을 설정합니다. 입력데이터는 매일 6개의 변수 ($x_t \in \mathbb{R}^6$)가 들어가므로 input_dim = 6 으로 설정하였습니다. 잠재변수를 h_dim = 3 ($h_t \in \mathbb{R}^3$)로 설정하여 입력데이터들이 3차원 변수로 변환하여 출력값으로 전달됩니다. 과거의 4일 데이터로 모형을 만들기에 ($x_{t-3}, \cdots, x_{t}$) seq_len = 4로 설정하였습니다. 하지만 seq_len = 4 는 rnn 모형의 인자는 아닙니다. 왜냐하면 rnn 은 rnn cell 하나를 정하는 것이므로 어떤 입력이 오고, 어떤 잠재변수를 전달할 것인지 정하는 것이기 때문입니다. num_layers 는 RNN cell 을 몇 층으로 구성할 것인지 정하는 것입니다. 여기서는 1이라고 두겠습니다. (자세한 사항은 다층 RNN 을 참고하세요)
# Define hyperparameters
input_dim = 6
seq_len = 4
h_dim = 3
learning_rate = 0.001
num_epochs = 100
rnn = nn.RNN(input_size = input_dim, hidden_size = h_dim,
num_layers = 1, batch_first = True)
rnn
이제 입력데이터를 구성할 차례입니다. 우리는 입력데이터 텐서를 (batch, seq, feature) 로 만들 것입니다. 즉, 첫번째는 관측치 인덱스에 두 번째는 길이 인덱스, 세 번째는 입력데이터의 변수 수를 나타냅니다. 예를 들어 하루에 대응되는 변수가 총 6개가 있는데, 과거 4일치 데이터를 한 세트로 만들어서 총 300 세트 (세트 마다 겹치겠지요)를 가지고 있다고 하면 데이터 형식을 (300, 4, 6)으로 구성합니다. 이 때 우리가 rnn cell 을 설정할 때 해주어야 하는 일이 있는데 바로 batch_first = True 으로 명시하는 것입니다. 만약 아무런 옵션설정을 하지 않는다면 batch_first = False 가 되고 데이터는 (seq, batch, feature) 이 되어야 합니다. 출력값 역시 Batch_first 옵션을 따릅니다 (중요!).
4일치 과거데이터를 묶어서 2세트를 만들어보겠습니다. x1 은 4행 6열 데이터입니다 x1 과 x2를 stack 으로 묶으면 (2,4,6) 크기를 가지는 배열이 됩니다.
# 2개 샘플 만들기
x1 = x[0:4,:]
x2 = x[1:5,:]
x_data = np.stack((x1,x2), axis = 0)
print(x_data)
x_data.shape
input = torch.tensor(x_data).float()
print(input.shape)
print(input.dtype)
다음은 rnn cell 의 잠재변수 초기값을 설정하는 코드입니다. Batch_first = True 와 상관없이 (num_layers*D, batch, hidden_size) 로 h0 를 입력합니다. (만약 bidirectional 이면 D = 2, 아니면 D = 1). 우리 예제에서는 1개 층, 2개 샘플, 3차원이므로 (1,2,3)를 입력합니다.
# 잠재변수의 초기화
h0 = torch.randn(1, 2, 3)
h0.dtype
output, hn = rnn(input, h0)
print("output")
print(output)
print(output.shape)
print("hn")
print(hn)
print(hn.shape)
다음 우리는 RNN 을 커스텀 모형을 만들 것입니다. __init__으로 초기화 되는 부분은 몇 개의 레이어 함수를 정의합니다. 여기서 rnn cell 은 Batch_first=True 이므로 output 의 형태는 (batch, seq, feature) 로 이루어집니다. 즉, output[0,:,:] 은 첫 번째 input에 대한 rnn feature 행렬인데, 행벡터가 input seq 대응되는 hidden feature 에 해당합니다. 예를 들어서 input[0,:,:] 의 첫행이 4일전 데이터, 두 번째 행이 3일전 데이터 에 대항할 것인데, output[0,:,:] 의 첫행은 4일전 데이터의 잠재변수, output[0,:,:] 의 두 번째행은 3일전 데이터의 잠재변수에 해당 할 것 입니다. 물론 잠재변수를 이미 3차원으로 정의했기 때문에 output[0,:,:]는 4행 3열 행렬입니다. 참고로 hn[:,0,:] 은 관측치 두개에 대한 마지막 hidden feature 값인데, 이는 convext vector 라 부르기도 합니다.
# Define the RNN model
class myRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super(myRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
out, _ = self.rnn(x, h0)
out = out[:, -1, :]
out = self.fc(out)
return out
그러면 데이터 세트를 만들어 보겠습니다. inout_seq 리스트에 (train_seq, train_label) 튜플을 쌓습니다. train_seq 는 과거 4일 데이터, train_label 예측 데이터를 채웁니다
# window size 설정
window_size = 4
# 입력 시퀀스와 출력 시퀀스 정의
def create_inout_sequences(input_data, y, window_size):
inout_seq = []
L = len(input_data)
for i in range(L - window_size):
train_seq = input_data[i:(i+window_size)]
train_seq = train_seq.astype(np.float32)
train_label = y[(i+window_size):(i+window_size+1)]
train_label = train_label.astype(np.float32)
inout_seq.append((train_seq ,train_label))
return inout_seq
train_data = create_inout_sequences(x, y, seq_len)
print('input:', train_data[0][0].shape)
print('output:', train_data[0][1].shape)
print('train_data:', len(train_data))
RNN 모형의 적합
이제 모형적합을 합니다. input_dim = 6, seq_len = 4, h_dim = 3 로 놓았습니다. 이를 확인하고 코드의 실행과정을 설명해봅시다.
# 모형적합
batch_size = 10
train_loader = torch.utils.data.DataLoader(train_data, shuffle=False, batch_size=batch_size)
model = myRNN(input_dim, h_dim, 1).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
optimizer.zero_grad()
num_epochs = 1000
model.train()
for epoch in range(num_epochs):
for inputs, labels in train_loader:
input = inputs.to(device)
label = labels.to(device)
output = model(input)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(loss)
마지막으로 적합된 데이터를 참값과 비교해봅니다.
# 예측값의 저장
model.eval()
true_vec = []
est_vec = []
with torch.no_grad():
for inputs, labels in train_loader:
input = inputs.to(device)
label = labels.to(device)
output = model(input)
est_vec.extend(output.numpy().squeeze(1))
true_vec.extend(label.numpy().squeeze(1))
import matplotlib.pyplot as plt
plt.plot(est_vec,true_vec, ".")
ko-FinBert 를 이용한 텍스트데이터의 활용
다음은 ko-finbert를 이용해 텍스트를 임베딩하는 코드입니다. 텍스트 데이터를 인공지능 모형의 입력으로 사용하기 위해서는 숫자로의 변환이 필요합니다. 이 변환 과정을 임베딩이라 부르는데, 인공지능 모형의 성능은 임베딩의 성능에 크게 의존합니다. 주어진 데이터를 통해 임베딩을 학습하거나, 만들어진 임베딩 모형을 미세조정하여 사용하기도 하지만 만들어진 임베딩을 그대로 사용하기도 합니다. 여기서는 임베딩한 데이터를 미리 만들어 RNN에 활용합니다. 아래 코드를 한 줄씩 실행하면서 어떤 일이 일어나는지 살펴봅시다.
# 텍스트 임베딩
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
# 허깅페이스의 transformers 모듈 사용
from transformers import BertModel, BertTokenizer, BertConfig
from transformers import AutoTokenizer, AutoModelForMaskedLM, AutoModel, AutoConfig
# 허깅페이스로부터 KR-FinBert-SC의 토크나이저와 모델을 불러옴
tokenizer = AutoTokenizer.from_pretrained("snunlp/KR-FinBert-SC")
model = AutoModelForMaskedLM.from_pretrained("snunlp/KR-FinBert-SC", output_hidden_states=True)
textdata = pd.read_csv("http://ranking.uos.ac.kr/class/DL1/textdata.csv")
text = list(textdata["text"])
encoded_input = tokenizer(text,
return_tensors='pt',
padding=True,
max_length=50,
truncation=True)
# 임베딩 수행
with torch.no_grad():
outputs = model(**encoded_input)
last_hidden_state = outputs.hidden_states[-1]
# CLS 토큰 임베딩
text_emb = last_hidden_state[:,0,:]
textdata 는 시계열 길이만큼의 경제 관련 짧은 텍스트들이 정리되어 있습니다. (주의! 이 텍스트는 사실 임의로 만들어 진 것이어서 우리 예제에서는 예측에 도움을 줄 수 없습니다.) tokenizer 는 텍스트 데이터를 토큰으로 분해합니다. 최대 길이를 50으로 지정하였습니다. 우리 예제에서는 최대 길이는 넘는 문장은 없습니다.
model 에 textdata 를 입력하여 텍스트 임베딩 값을 얻습니다. 임베딩의 품질을 개선하거나 경량화를 위해서 모형을 불러올때 다른 모형을 불러올 수 있습니다. 우리는 huggingface 에 있는 "snunlp/KR-FinBert-SC"를 불러왔습니다.
outputs.hidden_states 는 Bert 의 출력값이 레이어 별로 총 13개가 저장되어 있습니다. 우리는 최종 레이어에 있는 feature 를 가져오기 위해 outputs.hidden_states[-1] 을 사용합니다. last_hidden_state 는 문장의 길이 (pad 포함)만큼의 토큰 feature 가 저장되어 있습니다. 저장방식은 (batch, seq, feature) 입니다. 여기서 가장 첫 번째 토큰 (CLS)의 임베딩을 가져옵니다. 이 토큰은 문장 전체의 성격을 축약한다고 알려져 있습니다. 여기서 last_hidden_state.mean(dim=1) 과 같이 평균 임베딩을 사용하기도 합니다.
주가 데이터를 전처리 합니다.
# 주가 데이터 전처리
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
device = 'cuda' if torch.cuda.is_available() else 'cpu'
torch.manual_seed(1)
if device == 'cuda':
torch.cuda.manual_seed_all(1)
# Load data
df = pd.read_csv('http://ranking.uos.ac.kr/class/RB/stock_data.csv')
df.head()
x_0 = np.array(df['Close'][0:-1])
x_1 = np.array(df['Close'][1:])
x = np.log(1-(x_1-x_0)/x_0)
y = x.copy() # len(y)
x = x[:,np.newaxis] #x.shape
df1 = df.drop(index=df.index[-1])
df1 = np.array(df1)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df1 = scaler.fit_transform(df1)
시계열 입력에 텍스트 임베딩을 추가합니다. 이전 예제와 동일합니다.
# 텍스트 임베딩을 추가
x = np.concatenate( (x,df1, text_emb), axis = 1) # x.shape
모형과 데이터 전처리에 필요한 함수를 정의합니다.
# 모형 정의
# Define the RNN model
class myRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super(myRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device)
out, _ = self.rnn(x, h0)
out = out[:, -1, :]
out = self.fc(out)
return out
# 입력 시퀀스와 출력 시퀀스 정의
def create_inout_sequences(input_data, y, window_size):
inout_seq = []
L = len(input_data)
for i in range(L - window_size):
train_seq = input_data[i:(i+window_size)]
train_seq = train_seq.astype(np.float32)
train_label = y[(i+window_size):(i+window_size+1)]
train_label = train_label.astype(np.float32)
inout_seq.append((train_seq ,train_label))
return inout_seq
데이터 전처리를 수행하고 하이퍼파라메터를 설정합니다.
# 데이터 전처리
# Define hyperparameters
seq_len = 4
learning_rate = 0.001
num_epochs = 100
_, p = x.shape
# 입력 시퀀스와 출력 시퀀스 생성
window_size = 4
train_data = create_inout_sequences(x, y, window_size)
모형을 적합합니다.
# 모형적합
# 데이터를 batch 단위로 나누기
batch_size = 10
train_loader = torch.utils.data.DataLoader(train_data, shuffle=False, batch_size=batch_size)
model = myRNN(p, 3, 1).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.005)
optimizer.zero_grad()
num_epochs = 100
for epoch in range(num_epochs):
for inputs, labels in train_loader:
input = inputs.to(device)
label = labels.to(device)
output = model(input)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(loss)